
Zeppelin has become one of my favourite tools in my toolbox. I am heavily designing stuff for Cassandra and in Scala, and even though I love Cassandra there are times when things just gets so complicated with the CQL command line, and creating a small project in IntelliJ just seems like too much hazel. Then using Zeppelin to try out is just perfect. So this page is a How-To with some useful Cookbook recipes.
Setting Up Zeppelin
I use Docker where things are so much easier, and I pick v0.8.0 cause I never got 0.8.2 to work for some reason.
Download and Start Cassandra
|
1 |
docker pull cassandra |
|
1 |
docker run --name Cassandra3 -p 9042:9042 cassandra:3.11 |
Download and Start Zeppelin
Download Zeppelin image
|
1 |
docker pull apache/zeppelin:0.8.0 |
Start Zeppelin on port 8080
|
1 |
docker run -p 8080:8080 --name zeppelin apache/zeppelin:0.8.0 |
-p hp:cp
hp = Host Port, the port on your local machine
cp = Container Port, the port inside the docker which is what Zeppelin is exposing
Go to localhost:8080 in your web browser and you should see something like this
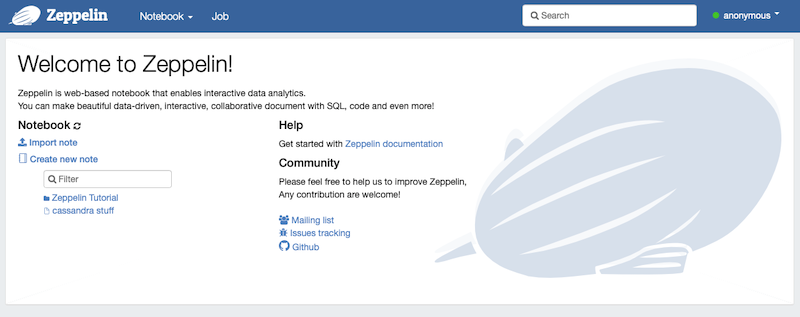
Setup Zeppelin
Find out the IP address of Cassandra in you Docker network, as you can see of the inspect, the IP address is 172.17.0.3.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
QSWEM078:~ teriksson$ docker network inspect bridge [ { "Name": "bridge", "Id": "355be8072aafa87bafa8de19d00af597746039000d27e9245e2464fa54bf81a8", "Created": "2020-04-03T14:23:57.446760383Z", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": null, "Config": [ { "Subnet": "172.17.0.0/16", "Gateway": "172.17.0.1" } ] }, "Internal": false, "Attachable": false, "Ingress": false, "ConfigFrom": { "Network": "" }, "ConfigOnly": false, "Containers": { "ceda1cebea87ee7244f00d5e88292ff76fc46142627ed4064e0b98cd92f728a3": { "Name": "zeppelin", "EndpointID": "2cc39278d16db811bc593945adcc4a7ae2d0e5409a98c1ddf0d548bcf0b7052a", "MacAddress": "02:42:ac:11:00:02", "IPv4Address": "172.17.0.2/16", "IPv6Address": "" }, "f772b8c66fe3729bd00e2bd9d2e50472ec40b1e8047796f8f69db6ecee6a77ae": { "Name": "<strong>cassandra3</strong>", "EndpointID": "23fde4a184ca9456ddec164616c4603f6ee8f3c310e21cb7c4409d350d7c3fd6", "MacAddress": "02:42:ac:11:00:03", "IPv4Address": "<strong>172.17.0.3</strong>/16", "IPv6Address": "" } }, "Options": { "com.docker.network.bridge.default_bridge": "true", "com.docker.network.bridge.enable_icc": "true", "com.docker.network.bridge.enable_ip_masquerade": "true", "com.docker.network.bridge.host_binding_ipv4": "0.0.0.0", "com.docker.network.bridge.name": "docker0", "com.docker.network.driver.mtu": "1500" }, "Labels": {} } ] |
Set up IP address for Cassandra in the Spark Interpreter

Go to the section on “Spark”
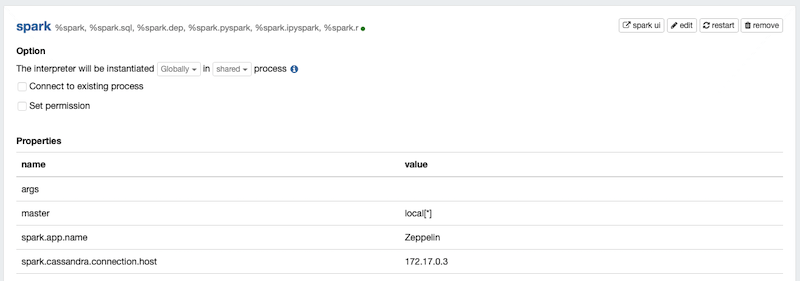
Now add a row that says
|
1 |
spark.cassandra.connection.host : <span class="ng-scope ng-binding editable">172.17.0.3 </span> |
Now also edit the Dependencies
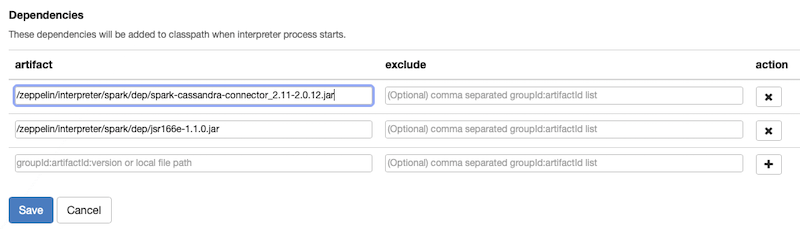
You can do this in many ways, either you specify the MAVEN repo with version OR you download the JAR file(s) to disk and copy them into the Docker. I had to do the latter due to some issue with my network.
You need these two libraries :
- https://mvnrepository.com/artifact/com.datastax.spark/spark-cassandra-connector_2.11/2.0.12
- https://mvnrepository.com/artifact/com.twitter/jsr166e/1.1.0
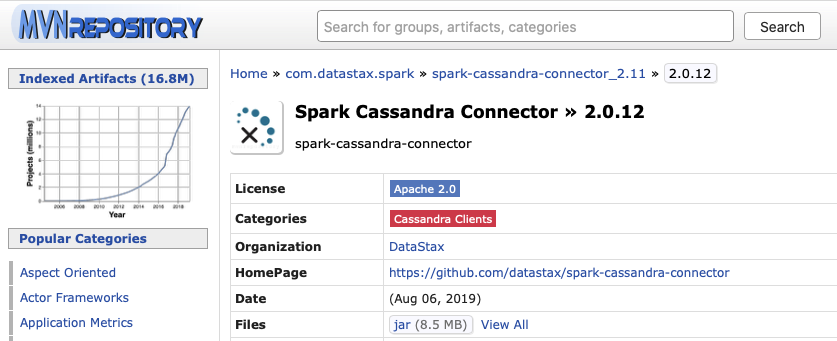
Simply click on the JAR file and download the file, then copy it into the docker with
|
1 |
docker cp spark-cassandra-connector_2.11-2.0.12.jar zeppelin:/zeppelin/interpreter/spark/dep/spark-cassandra-connector_2.11-2.0.12.jar |
|
1 |
docker cp jsr166e-1.1.0.jar zeppelin:/zeppelin/interpreter/spark/dep/jsr166e-1.1.0.jar |
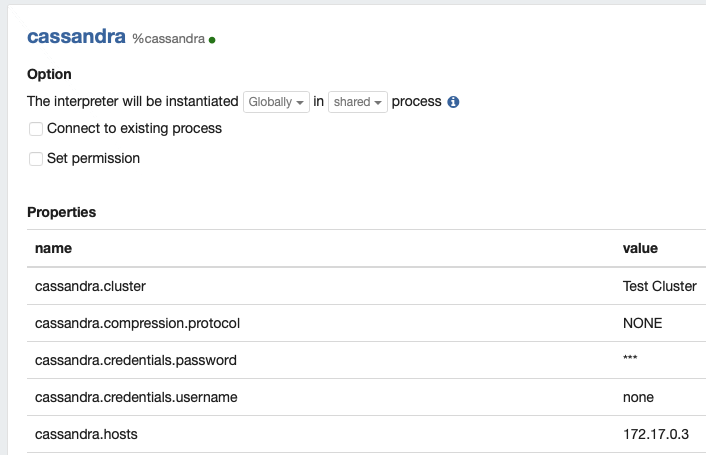
Setup IP address for Cassandra in Cassandra Interpreter
|
1 |
cassandra.hosts : 172.17.0.3 |
Create your first Notebook

Cookbook Recipes
Load Table into RDD and count rows
This is just to show how you load a table into an RDD, once in the RDD you can play around with it and do lots of stuff.
|
1 2 3 4 5 6 7 |
%spark import com.datastax.spark.connector._ import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.SparkContext._ val rdd = sc.cassandraTable("system_schema","keyspaces") println("Row count:" + rdd.count) |
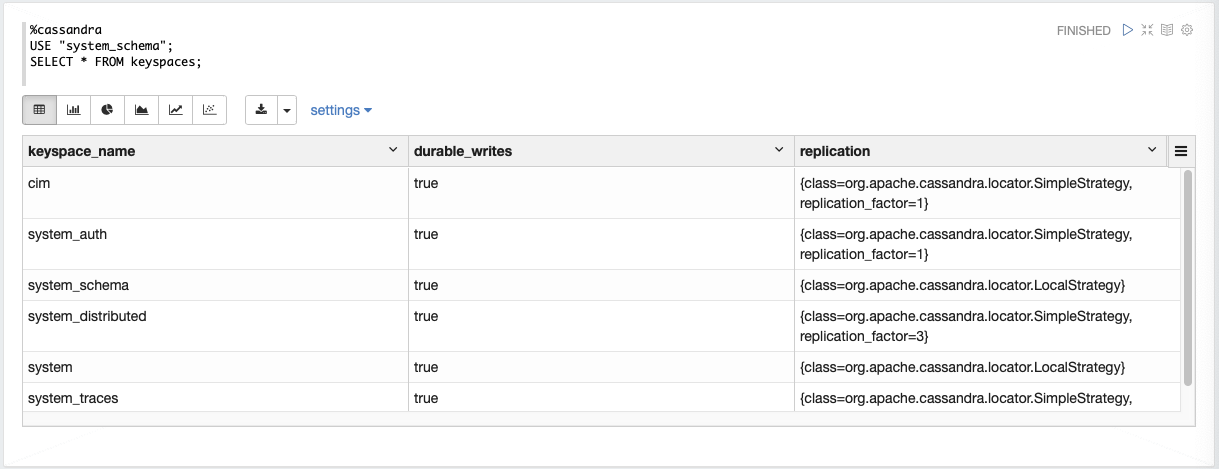
Show key spaces using the built in Cassandra interpreter using CQL
|
1 2 3 4 |
%cassandra USE "system_schema"; SELECT * FROM keyspaces; |
The result :
Create Keyspace and Table using CQL
|
1 2 3 |
%cassandra CREATE KEYSPACE cim WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 1}; |
|
1 2 3 4 5 6 7 |
%cassandra CREATE TABLE cim.customer( id int PRIMARY KEY, name text, city text, ); |
Insert data by hand using CQL
|
1 2 3 |
%cassandra INSERT INTO cim.customer_fast (id, ck1, name, city ) VALUES ( 1,2, 'US Robotics', 'New York' ); |
Fill the table with bogus data using Spark and Scala
|
1 2 3 4 5 6 7 8 9 |
%spark import scala.util.Random val random = new Random val cities = List[String]( "Stockholm", "Malmoe", "Kalmar", "Jonkoping", "Linkoping", "Karlskrona", "Ronneby" ) val companyNames = List[String]( "Ikea", "SJ", "Ericsson", "Thai Silk", "Italia", "Apple", "ASEA", "Pressbyran") val data = (1 to 3000 ).map( id => (id,companyNames(random.nextInt(companyNames.length))+"-"+id,cities(random.nextInt(cities.length))) ) val rdd = sc.parallelize( data ) rdd.saveToCassandra( "cim", "customer", SomeColumns("id","name","city") ) |
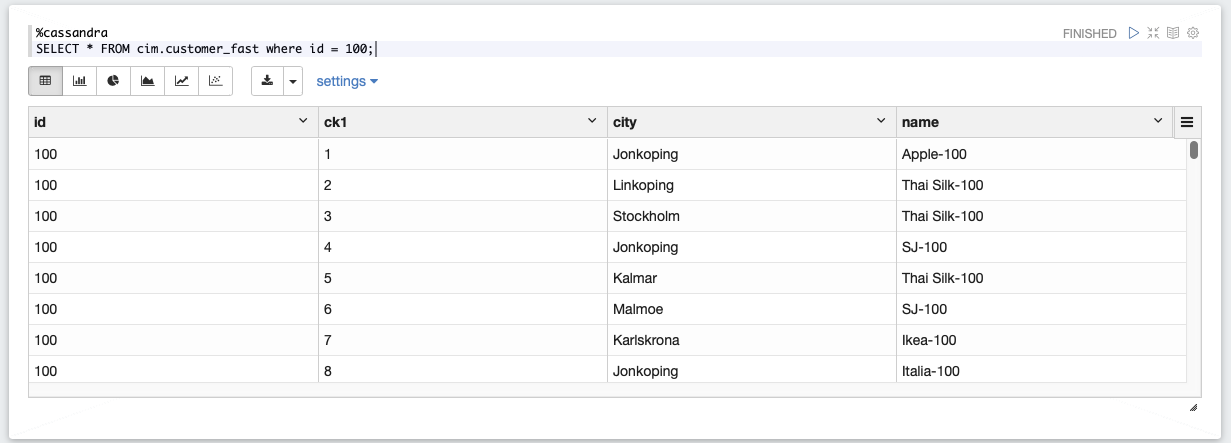
Select data using CQL
|
1 2 3 |
%cassandra SELECT * FROM cim.customer_fast where id = 100; |
Create VIEW so that we can run SQL
|
1 2 3 4 5 6 7 8 9 10 11 |
%spark import org.apache.spark.sql.cassandra._ import org.apache.spark.sql val createTempView = """CREATE TEMPORARY VIEW customers USING org.apache.spark.sql.cassandra OPTIONS ( table "customer", keyspace "cim", pushdown "true")""" spark.sql(createTempView) |
Run SQL, ohh sweet SQL 🙂
|
1 2 3 |
%spark spark.sql("SELECT * FROM customers WHERE city like 'K%' limit 10").show |

By creating temporary views like this, we can also do joins if we would like to.
Obviously this is not how Cassandra was intended to be used, but the point here is more of giving the ability to troubleshoot, turist around in the data with ease instead of setting up a project, and do the joins inside of the code. Here we are able to really trail and error until we get what we want.
That was all for now
-Tobias
how it using Zeppelin to try out?
Thanks, I have recently been looking for info about this topic for ages and yours is the best I’ve discovered so far.
thank you for your information,what’s next?
Good article, thanks for sharing, please visit
our website
Thanks, I have recently been looking for info about this topic for ages and yours is the best I’ve discovered so far.
I am very interested in the information contained in this post. The information contained in this post inspired me to generate research ideas. Thank You.
yes you are right…Apache Cassandra is an open-source distributed NoSQL database management system built to handle large chunks of data over various data centers. Cassandra was developed at Facebook to overcome its “inbox search” issue and make it easier to find the conversations. Facebook later open-sourced Cassandra, and it became an Apache Foundation project. Cassandra is a highly scalable database and is freely available under the Apache License 2.0.
will you share another way?
Howdy! I just woud like to give you a huge thumbs up foor your great info you’ve got here on this post. I’ll be coming back to your site for more soon. is there a special schedule for posting?
Thank you for nice information. Please visit our web:
https://uhamka.ac.id
do you want to continue the development of your website?
Thanks for article~
Visit Website Us :
ITTELKOM JAKARTA
Thank for the information, please visit
VisitUs
Your ideas absolutely shows this site could easily be one of the bests in its niche. Drop by my website Webemail24 for some fresh takes about Search Engine Optimization. Also, I look forward to your new updates.
Your writing style is cool and I have learned several just right stuff here. I can see how much effort you’ve poured in to come up with such informative posts. If you need more input about Social Media Marketing, feel free to check out my website at Seoranko
Your blog has really piqued my interest on this topic. Feel free to drop by my website ArticleHome about Data Mining.
Hey, I enjoyed reading your posts! You have great ideas. Are you looking to get resources about Car Purchase or some new insights? If so, check out my website Autoprofi
Great post! I learned something new and interesting, which I also happen to cover on my blog. It would be great to get some feedback from those who share the same interest about Tantric Massage, here is my website Articlecity Thank you!
My site Articleworld covers a lot of topics about Online Music Streaming and I thought we could greatly benefit from each other. Awesome posts by the way!
Impressive posts! My blog Article Sphere about PR Marketing also has a lot of exclusive content I created myself, I am sure you won’t leave empty-handed if you drop by my page.
Hey there, I appreciate you posting great content covering that topic with full attention to details and providing updated data. I believe it is my turn to give back, check out my website YW9 for additional resources about Airport Transfer.