Here are some notes on how to get on with Lua scripting for KrakenD
Imagine you have a backend that returns a JSON like this
|
1 2 3 4 5 6 7 8 9 10 11 |
{ "databaseId": "931cd556-4ce3-4bea-80c7-a2b754988321", "dateOfBirth": "1956-10-20", "firstName": "Olivia", "id": 45, "job": "Scientist, clinical (histocompatibility and immunogenetics)", "lastName": "Robles" } The KrakenD setup is like this |
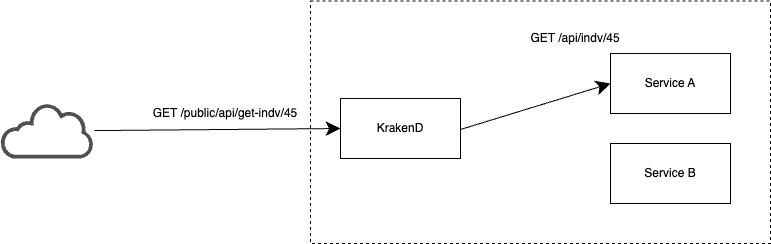
So we route
| KrakendD | Service A |
| GET /public/api/get-indv/45 | GET /api/indv/45 |
The most basic KrakendD config would be something like this
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "endpoint": "/public/api/get-indv/{id}", "method": "GET", "output_encoding": "json", "input_headers": [ "*" ], "backend": [ { "host": [ "http://service_a_1:5059" ], "url_pattern": "/api/indv/{id}", "method": "GET", "encoding": "json" } ] } |
In fact you could remove the ‘output_encoding’ and ‘encoding’, cause those are ‘json’ by default but gives clarity to the example.
Remove unwanted fields from the JSON
Let’s say that we do not want to expose the field “databaseId” Then we can apply a Lua script in KrakenD that solves this for us The configuration in krakendD can look something like this
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
{ "endpoint": "/public/api/get-indv/{id}", "method": "GET", "output_encoding": "json", "input_headers": [ "*" ], "backend": [ { "host": [ "http://service_a_1:5059" ], "url_pattern": "/api/indv/{id}", "method": "GET", "encoding": "json", <mark style="background-color:#fbca3c" class="has-inline-color">"extra_config": { "modifier/lua-backend": { "sources": [ "common_lua_functions.lua" ], "post": "remove_unwanted_fields_from_json(response.load())", "live": true, "allow_open_libs": true, "skip_next": false } }</mark> } ] } |
The Lua code we place in a file on the same directory as the krakenD config
And the Lua function could look something like this
|
1 2 3 4 5 6 7 8 9 10 |
function remove_unwanted_fields_from_json(resp) -- When the encoding is 'json' then the Data-object -- contains the JSON structure in a luaTable -- Here we can access the content of the json through -- data:get(key) see example below local data = resp:data() <mark style="background-color:#fbca3c" class="has-inline-color">data:del('databaseId') </mark> end |
Dump some request info and the Data-object to the KrakenD log
Let’s place the lua script to dump some info on the ‘proxy’ level, the config could look something like this
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
{ "endpoint": "/public/api/get-indv-dump-req-info/{id}", "method": "GET", "output_encoding": "json",<mark style="background-color:#fbca3c" class="has-inline-color"> "extra_config": { "modifier/lua-proxy": { "sources": [ "common_lua_functions.lua" ], "pre": "print_request_info(request.load()); ", "post": "print_all_data_fields(response.load()); ", "live": true, "allow_open_libs": true, "skip_next": false } },</mark> "input_headers": [ "*" ], "backend": [ { "host": [ "http://service_a_1:5059" ], "url_pattern": "/api/individuals/{id}", "method": "GET", "encoding": "json", "extra_config": { "backend/http": { "return_error_code": true } } } ] } |
The Lua code
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
function print_request_info(r) print("- - - - - - - - - - - - - - - Dump some Request info - - - - - - - - - - - - - - - ") print(type(r)) print("URL: "..r:url()) print("Method:"..r:method()) print("path:"..r:path()) print("query:"..r:query()) print("- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -") end function print_all_data_fields(resp) print("- - - - - - - - - - - - - - - Dump Data Object - - - - - - - - - - - - - - - ") local data = resp:data() local keys = data:keys() local stop = keys:len() - 1 print("These are the Keys") for idx=0,stop do print(tostring(idx).." : "..keys:get(idx)) end print("These are the Keys and Values") for idx=0,stop do print(keys:get(idx).." = "..data:get(keys:get(idx))) end print("- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - ") end |
Set or Modify the body when it is Content-Type : text
Note that KrakenD needs to be told how to interpret the data, and above the encoding was set explicitly to ‘json’ here we will set it to ‘string’ (i.e. text). The KrakenD config could look something like this
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
{ "endpoint": "/public/api/get-data-modify-body/{id}", "method": "GET", <mark style="background-color:#fbca3c" class="has-inline-color">"output_encoding": "string",</mark> "extra_config": { "modifier/lua-proxy": { "sources": [ "common_lua_functions.lua" ], <mark style="background-color:#fbca3c" class="has-inline-color">"post": "replace_body_content(response.load()); ",</mark> "live": true, "allow_open_libs": true, "skip_next": false } }, "input_headers": [ "*" ], "backend": [ { "host": [ "http://service_a_1:5059" ], "url_pattern": "/api/indv/{id}", "method": "GET", <mark style="background-color:#fbca3c" class="has-inline-color">"encoding": "string",</mark> "extra_config": { "backend/http": { "return_error_code": true } } } ] } |
The Lua code below
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function replace_body_content(resp) -- When the encoding is set to 'string' then the Data-object -- contains only ONE key 'content'. And it is just a test -- string that we can modify as we like local data = resp:data() data:set('content','{ "messsage": "now the body has changed!" }' ) -- local keys = data:keys() -- data:set(keys:get(0), '{ "messsage": "body has changed!"}') end |
Note that when we would like to modify the body and the data-object key will be ‘content’.
Set the http header Content-Type from Lua script
Imagine that the encoding/output_encoding was set to ‘string’ then the return data from krakenD will set the Content-Type to ‘text/plain; charset=utf-8’
If you would for some reason get a string and would like to set the Content-Type to ‘application/json; charset=utf-8’
You can do this from a Lua script like this
|
1 2 3 4 |
function set_content_type_to_json(resp) resp:headers("Content-Type","application/json") end |
Bless you !
-Tobias